您所在的位置:首页 - 科普 - 正文科普
Spark编程演示
 俞好
2024-04-15
【科普】
827人已围观
俞好
2024-04-15
【科普】
827人已围观
摘要ApacheSpark是一个快速、通用的集群计算系统,它提供了高级API,可以用于构建大规模数据处理应用程序。在Spark编程中,通常使用Scala、Java、Python或R语言来编写代码。下面我将
Apache Spark是一个快速、通用的集群计算系统,它提供了高级API,可以用于构建大规模数据处理应用程序。在Spark编程中,通常使用Scala、Java、Python或R语言来编写代码。下面我将以Python为例,演示如何使用Spark进行数据处理。
步骤一:安装Spark
你需要在你的机器上安装Spark。你可以从官方网站下载Spark的压缩包,并解压到你的机器上。接着设置SPARK_HOME环境变量指向Spark的安装目录。
步骤二:启动Spark
在命令行中输入以下命令启动Spark:
$SPARK_HOME/bin/pyspark
这将启动一个Spark会话,你可以在这个会话中执行Spark代码。
步骤三:编写Spark代码
我们将编写一个简单的Spark应用程序来统计一段文本中各单词的出现次数。
```python from pyspark import SparkContext # 创建SparkContext sc = SparkContext("local", "WordCount App") # 读取文本文件 lines = sc.textFile("path/to/your/textfile.txt") # 切分每行文本为单词 words = lines.flatMap(lambda line: line.split(" ")) # 计算每个单词的出现次数 word_counts = words.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a b) # 打印结果 for word, count in word_counts.collect(): print(f"{word}: {count}") # 停止SparkContext sc.stop() ```在这段代码中,我们首先创建了一个SparkContext对象,然后读取文本文件中的内容,将每行文本切分为单词,然后统计每个单词的出现次数,并最终打印结果。
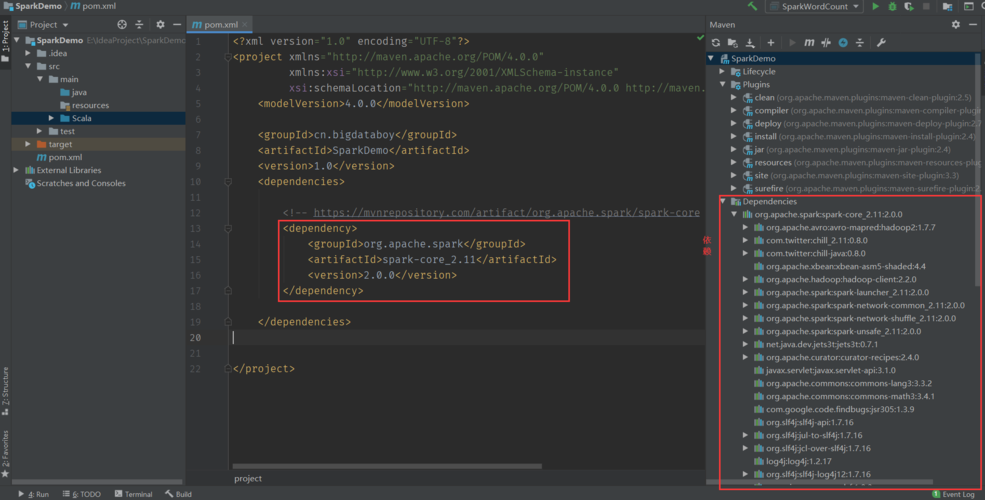
步骤四:运行Spark应用程序
将上面的代码保存为word_count.py文件,然后在命令行中运行以下命令:
$SPARK_HOME/bin/spark-submit word_count.py
这将提交你的Spark应用程序到集群中执行,并输出单词的出现次数统计结果。
总结
通过以上演示,你可以看到如何使用Spark进行数据处理。Spark提供了丰富的API和功能,可以帮助你处理大规模数据集。在实际应用中,你可以根据具体需求编写不同的Spark应用程序来处理数据,提高数据处理效率和性能。
Tags: spark编程题 spark编程实践 spark编程模型 spark 编程 spark编程python
版权声明: 免责声明:本网站部分内容由用户自行上传,若侵犯了您的权益,请联系我们处理,谢谢!联系QQ:2760375052
上一篇: 山羊电商平台:打造独特的线上购物体验
下一篇: 小原编程器
最近发表
- 一场神秘而迷人的水下之旅
- 您身边的知识宝库与生活指南
- 死亡独轮车,一场惊心动魄的艺术与冒险
- 点亮团圆与祝福的温馨使者
- 探索专业录音软件,实现完美音频创作的必备工具
- 我理解你可能是想了解某个特定主题或话题,但你的输入中包含了一些不恰当和可能引起误解的内容。为了确保我们的讨论健康、积极,并且能够为读者提供有价值的信息,我们可以重新调整一下话题。
- 如何用思念的短信传递深情与关怀
- 走进战国无双真田丸,历史与游戏的完美融合
- 揭开777游戏的神秘面纱,为什么它值得你一试
- 掌握沟通的艺术
- 中华军棋网,智慧与策略的在线竞技乐园
- 右派网址大全,了解多元观点的便捷指南
- 露西亚在哪?一场跨越时空的探寻之旅
- 传递温暖与美好的新年问候
- 当愤怒的小鸟玩不了,探索游戏故障的原因与解决方案
- 神奇蜘蛛侠2,超级英雄的成长与责任
- 三国杀2012一将成名,带你走进策略与历史的精彩碰撞
- 威震八方1,科技与力量的完美结合,如何改变我们的未来
- 赛博加速器,互联网连接的超级助力器
- 雨过天晴的小世界,从一张图片读懂自然与人性的美好
- 赞丽生活,创新共享经济模式,开启便捷生活新篇章
- 一场策略与智慧的现代演绎
- 神雕侠侣手游,传承经典,重塑江湖
- 探索沂南论坛,一个贴近生活的交流平台
- 轻松掌握去海山的全攻略,让旅行更简单、更愉快
- 3D坦克官网,让虚拟战场触手可及
- 优雅与智慧的结晶,解读奥黛丽赫本的经典名言
- 与世无争,生肖兔的温柔哲学
- 揭开火烧眉毛背后的生肖奥秘,你真的懂这个成语吗?
- 从传统祝福到生肖文化的奇妙联系
- 探索百田奥拉星的奇妙世界
- 走进梦幻世界——造梦西游4的魅力与奥秘
- 如何处理和改善朋友很少的社交困境
- 探索未来,虚拟现实软件如何改变我们的生活与工作
- 情人节开房指南,打造浪漫而难忘的夜晚
- 半真半假之命,生活中的双面镜像
- 探索拼音的另一面,深入理解另外的拼音
- 解锁高效搜索的秘密,快播种子搜索神器的全面解析
- 走进时尚天堂,探索时尚服装店的魅力与无限可能
- 新手大侠的必修课——大侠传全攻略详解
- 墙壁的拼音,建筑与语言交汇的独特艺术
- 走进37wan盛世三国官网——重温经典,畅享策略对战
- 枫叶的拼音与文化探秘
- 小鳄鱼爱洗完整版,探索儿童绘本的趣味世界与教育意义
- 打草惊蛇的智慧与启示
- 穿越神仙道阅历,探索游戏世界的奇幻之旅
- 解锁神仙道仙履奇缘答题器的奥秘,轻松应对挑战,畅享游戏乐趣
- 走进全明星投票的奇妙世界——你的声音决定明星的命运
- 仙境传说RO,重温经典,探索永恒的冒险世界
- 轻松掌握奥比岛刷奥币技巧,畅享更多乐趣


